Construction et Recherche de la Base de Données PeptideAtlas
Introduction à la Base de Données
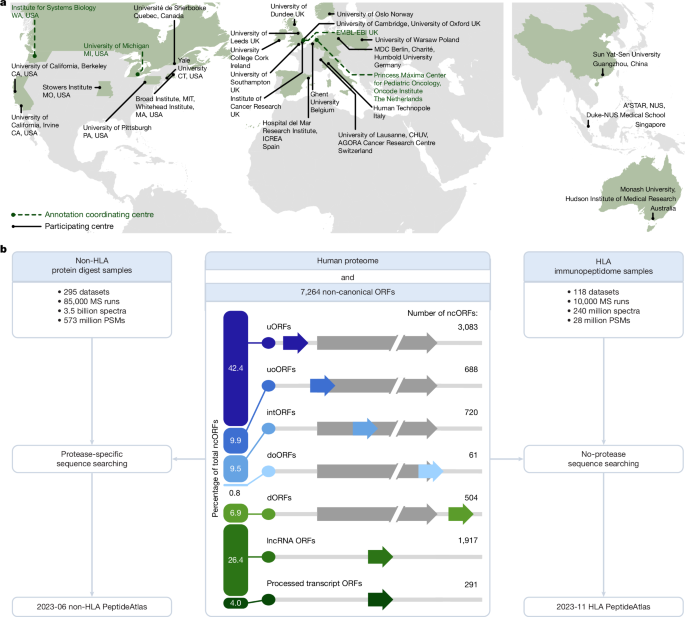
La construction de la base de données PeptideAtlas non HLA pour l’année 2023 a permis d’intégrer 295 ensembles de données ProteomeXchange (PXDs) à travers 1 172 expériences, totalisant 3,5 milliards de spectres MS/MS. L’identification des séquences a été réalisée à l’aide de MSFragger v.3.7, configuré selon les spécificités de chaque ensemble de données, tenant compte de divers paramètres tels que l’alkylation, la stratégie d’enrichissement et bien plus. Un ensemble de paramètres de recherche semi-enzymatique a été appliqué pour tous les ensembles.
Validation Statistique
Les résultats de chaque expérience ont été validés au moyen du Trans-Proteomic Pipeline (TPP) v.7.0. Les outils PeptideProphet, iProphet et PTMProphet ont été utilisés pour cartographier les données sur le protéome humain. Les variations connues ont été prises en compte, tant dans les résultats de recherche que dans les bases de données génétiques.
Détails des Données HLA
La version HLA de PeptideAtlas pour 2023 comprend 118 ensembles de données disponibles publiquement, divisés en 592 expériences et contenant 240 millions de spectres MS/MS issus de 9 776 analyses. Les recherches ont été menées en mode sans enzyme, et bien que certains peptides HLA exhibent des motifs de fragmentation typiques, de nombreux peptides HLA présentent des caractéristiques différentes, ce qui influe sur les résultats de spectrométrie.
Méthodologie de Recherche et Évaluation
Un processus innovant a été utilisé pour estimer le taux de faux positifs lors de la détection des ncORFs. En intégrant un échantillon de séquences ciblées avec des séquences leurres, le système a pu évaluer la précision des résultats obtenus. Les ajustements prennent en compte diverses modifications variables, telles que l’oxydation de la méthionine et de l’acétylation des protéines, afin d’optimiser la qualité des identifications.
Catégorisation des Protéines
Les peptides ont été cartographiés selon différentes catégories en fonction des critères établis par PeptideAtlas. Les protéines ayant deux peptides uniques ont été classées comme canonique, tandis que d’autres catégories comprennent des représentants indistincts et des preuves insuffisantes. Cela permet de mieux comprendre la diversité des protéines détectées.
Inspections Manuelles et Validation
Des inspections manuelles ont été mises en place pour minimiser les faux positifs, surtout dans le cadre d’identifications exceptionnelles relayées par les peptides. Chaque peptide a été évalué pour déterminer la solidité de l’identification, allant d’excellente à insuffisante, renforçant ainsi la fiabilité des résultats.
Annotation Génétique et Profilage
Le projet GENCODE a été la base pour annoter les gènes, et chaque ncORF identifié a été classé selon divers critères de provenance. Ceci a permis de distinguer l’expression dans les tissus cancéreux et non cancéreux, ainsi que de déterminer l’impact potentiel des ncORFs sur la biologie du cancer.
Analyse et Perspectives Futures
Les résultats de cette étude ouvrent des avenues passionnantes pour la recherche génétique, particulièrement en ce qui concerne les impacts des ncORFs sur diverses pathologies. Des analyses supplémentaires sont nécessaires pour valider des hypothèses sur l’efficacité des cibles thérapeutiques potentielles.
Points à retenir
- La base de données PeptideAtlas a été enrichie de millions de spectres pour optimiser l’identification des peptides.
- Des méthodes statistiques avancées ont été utilisées pour valider les résultats et minimiser les erreurs.
- La catégorisation des protéines facilite la compréhension de la diversité et de la complexité protéique.
- L’annotation des ncORFs peut éclairer des pistes sur leur rôle dans le cancer, offrant un champ d’étude prometteur.
En tant que passionné par l’évolution des données protéomiques, je trouve fascinant de voir à quel point des outils comme PeptideAtlas transforment notre compréhension des mécanismes biologiques. Ce domaine de recherche continuera d’évoluer, révélant sans aucun doute des découvertes inattendues qui pourraient changer notre approche des traitements médicaux et de la biologie humaine. Les possibilités qui s’offrent à nous sont infinies, et chaque avancée peut potentiellement nous rapprocher d’une meilleure compréhension des maladies complexes.